📌 Key Takeaways
Operations and QA stop fighting over traceability when both teams approve the same minimum standard before problems hit.
- Share One Rulebook: When both teams agree upfront on what “traceable” means, every quality problem follows a playbook instead of starting a turf war.
- Trace Units, Not Batches: Linking test data to individual units lets you isolate failures fast without freezing the whole production line.
- Gates Must Be Physical: A quality checkpoint that workers can skip under pressure isn’t a real checkpoint — route controls should block units that haven’t passed.
- Tag New-Process Units Separately: Marking new-product or engineering-change units with their own identifier keeps trial runs from getting mixed into steady-state production data.
- Pilot One Product First: Testing the protocol on a single product family through one real engineering change replaces theoretical arguments with measurable results.
Same standard, fewer shutdowns, faster fixes.
Operations Directors and QA Managers evaluating OEM traceability protocols will find a ready-to-use approval checklist here, preparing them for the detailed framework that follows.
~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~
The production line is running. A unit flags at the in-process checkpoint — but nobody can tell whether it’s an isolated component failure or tolerance drift rippling through the last 200 boards.
Operations wants to keep the line moving. QA wants to quarantine everything until root cause is confirmed. Two teams, both protecting the same program, pulling in opposite directions because there’s no shared standard for what “traceable” actually means.
This tension isn’t a personality conflict. It’s a protocol gap. When Operations and QA haven’t agreed on which traceability protocols are non-negotiable, every quality escape becomes a jurisdiction argument — and every approval cycle stalls while both sides re-litigate the basics. A shared framework changes that conversation entirely.
Why Operations and QA Stall on Traceability Approvals
The disconnect is structural. Operations Directors evaluate traceability through the lens of line continuity: will this protocol create bottlenecks, slow throughput, or force broad stoppages every time a unit fails? QA Managers evaluate the same protocol through the lens of defect exposure: can the line skip a check, can failures trace to specific units, and will the data survive an audit?
Put differently, Operations is trying to avoid friction — controls that add delay, create manual work, or force broad quarantines feel like a threat to output. QA is trying to avoid blind spots — a control that looks fine on paper but allows units to bypass checks or lose test history feels like a risk waiting to mature.
Both concerns are valid. The stall happens when neither team has a shared document defining what “good enough” looks like for both sides.
A common pitfall is treating traceability as a QA-only control that Operations must accept. That framing guarantees resistance. The more effective approach treats traceability as shared infrastructure — protecting line continuity just as much as defect containment. That principle aligns with broader traceability guidance from organizations like GS1 and governance frameworks reflected in NIST’s traceability work: traceability delivers the most value when identification, event capture, and process control are tied together to support decisions, not just audits.
What Operations Needs from a Traceability Protocol
For Operations, the nightmare isn’t a single defective unit. It’s a plant-wide freeze triggered by a quality escape nobody can scope.
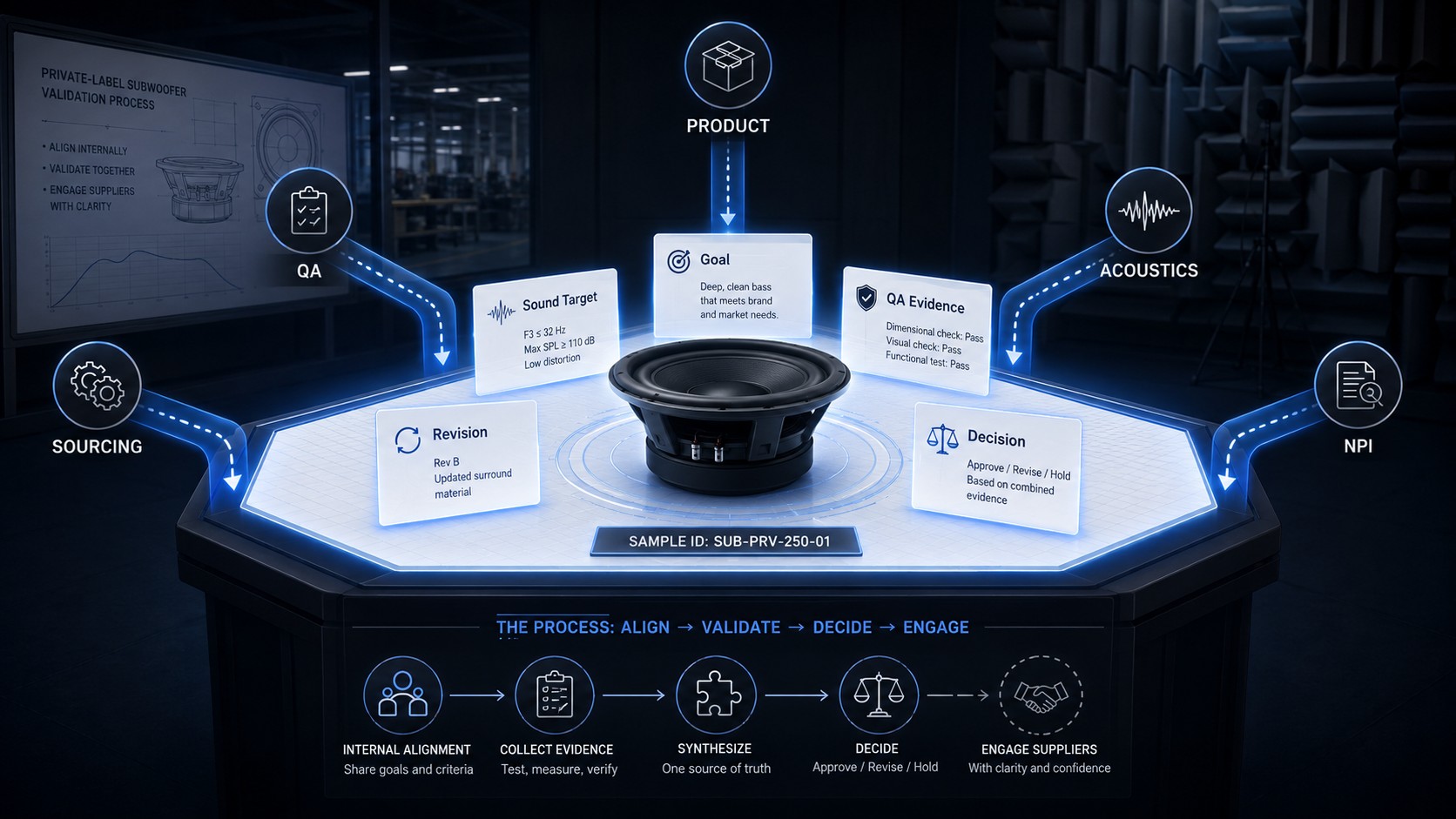
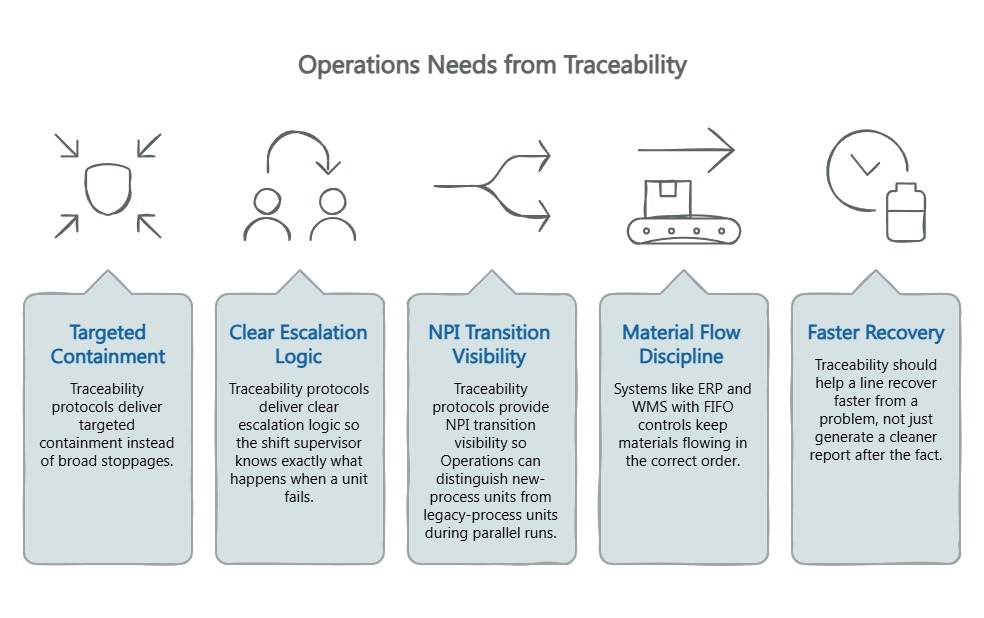
Traceability protocols that work for Operations deliver targeted containment instead of broad stoppages. When test data binds to individual unit identities, a failure at any gate traces to the affected lot or component batch — without freezing the entire line. They also deliver clear escalation logic so the shift supervisor knows exactly what happens when a unit fails, and NPI transition visibility so Operations can distinguish new-process units from legacy-process units during parallel runs.
Systems like ERP and WMS with FIFO controls keep materials flowing in the correct order. That discipline becomes far more valuable when connected to unit-level traceability: you trace a flagged unit backward through material flow, not just forward through test results.
The point is straightforward: traceability should help a line recover faster from a problem, not just generate a cleaner report after the fact. Operations doesn’t resist traceability because it’s unnecessary. It resists traceability that creates friction without delivering containment precision.
What QA Needs from a Traceability Protocol
For QA, the nightmare is the silent failure — spec-drift that passes visual inspection but surfaces six months later as unexplained warranty cost, with no data trail explaining what changed.
QA needs gate enforcement that cannot be bypassed. A protocol allowing units to skip stations under production pressure isn’t a protocol — it’s a suggestion. Testing route control must physically prevent a unit from progressing without a logged pass. QA also needs test-data binding — barcodes or QR codes that control the testing route and bind results to each unit’s unique identity. Tools like KLIPPEL QC paired with golden sample governance provide objective, repeatable measurement benchmarks across a quality system spanning IQC, IPQC, FQC, and reliability testing.
A traceability protocol is only as strong as its enforcement. A documented gate that can be skipped under pressure is not really a gate. That principle is consistent with the broader quality-management discipline behind ISO 9001: consistency depends on controlled processes, documented responsibilities, and verifiable records.
QA doesn’t want to slow the line. QA wants proof that the line cannot quietly outrun its own controls.
The Shared Approval Framework: 5 Requirements Both Teams Should Sign Off On
Rather than negotiating from scratch, both teams can evaluate any proposed protocol against five shared criteria:
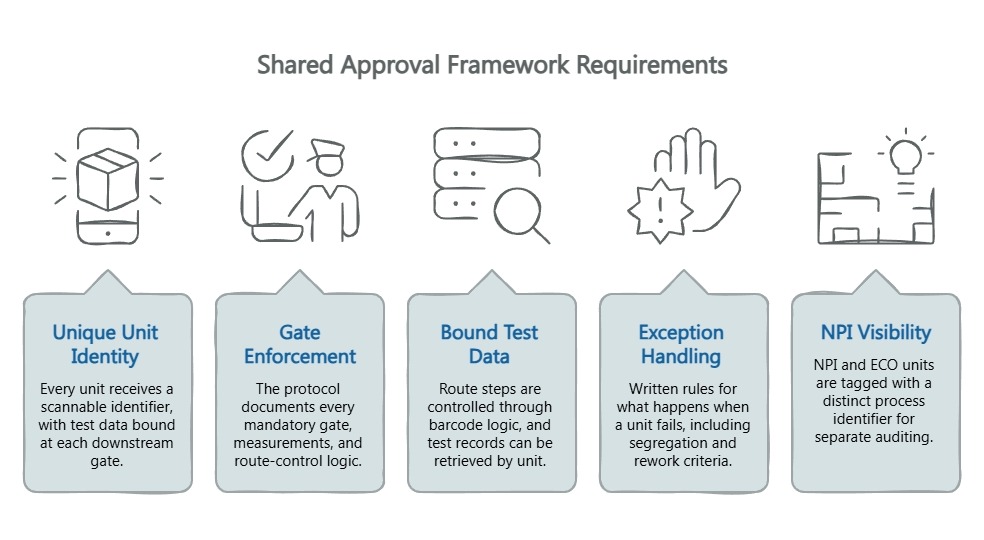
1. Unique Unit Identity and Data Binding. Every unit receives a scannable identifier before the first test station, with test data bound at each downstream gate. Operations gets precise containment; QA eliminates guesswork.
2. Gate Enforcement Across IQC, IPQC, and FQC. The protocol documents every mandatory gate, the measurements performed, and route-control logic preventing gate-skipping. Operations gets predictable cycle times; QA gets enforcement.
3. Bound Test Data and Route-Control Proof. Route steps are controlled through barcode or QR logic, and test records can be retrieved by unit. Operations gets route clarity that reduces rework chaos; QA gets test results that function as usable evidence, not disconnected files.
4. Exception Handling and Containment Logic. Written rules for what happens when a unit fails — segregation, rework criteria, and trigger conditions for escalating from unit-level to lot-level containment. Both teams get a playbook instead of a conference call.
5. NPI and Engineering-Change Visibility. NPI and ECO units are tagged with a distinct process identifier so both teams can audit transitions separately from steady-state production. The protocol shows how traceability remains visible during NPI transitions and engineering changes, including cutover points and revision visibility. For more on this alignment, see this guide on IPQC/FQC protocol alignment.
Here’s what that framework looks like as a quick-reference alignment tool:
| Requirement | Operations Priority | QA Priority | “Good Enough to Approve” |
|---|---|---|---|
| Unit identity | Scoped containment | Data traceability | Scannable ID bound to test data at every gate |
| Gate enforcement | Predictable cycle time | No bypasses | Route control prevents progression without logged pass |
| Bound test data | Route clarity, less rework chaos | Usable evidence per unit | Test records retrievable by unit through barcode/QR logic |
| Exception handling | Fast, defined response | Isolation before spread | Written rules per gate with rework and escalation triggers |
| NPI visibility | No mixed-process pallets | Validated transition data | NPI/ECO units tagged and auditable separately |
| Escalation rules | Measured response, no panic | Pattern detection | Documented thresholds and notification chains |
A short example makes the value concrete. A unit fails at a gate. Because the protocol binds test data to unit identity, QA isolates the affected stream quickly. Operations does not need to freeze the entire line or quarantine a much larger batch than necessary. The escalation rules define who is alerted, what is held, and how the affected stream is isolated — no conference call required.
A Low-Friction Pilot Path for Approval
The fastest way to stall a traceability initiative is to propose a wall-to-wall rollout on day one.
A sensible pilot has three characteristics: one product family, one defined gate sequence, and one agreed review window. That keeps the discussion concrete. Instead of arguing over every future scenario, both teams can check whether the protocol actually proves route enforcement, isolates failures cleanly, and preserves flow under normal production pressure.
Run the pilot through at least one NPI cycle or engineering change. Measure containment speed, false-positive rate at gates, and whether throughput actually drops under the new protocol. The pilot replaces theoretical arguments with observable results — and limits risk to one product family instead of the entire factory.
The China Future Sound factory evaluation checklist provides a structured 30-point assessment covering quality systems and traceability infrastructure that complements this pilot approach. For teams evaluating OEM partners more broadly, the amplifier manufacturing capabilities page offers additional context on production infrastructure.
Questions to Ask Before You Approve Any OEM Traceability Protocol
These questions reveal whether a protocol is enforced or merely documented:
- Can the OEM prove a unit cannot progress without a logged pass? Ask for a live demonstration of route-control enforcement — not just a process flowchart.
- Are failures isolated to units or components — not whole batches? If the answer is “we quarantine the batch,” that’s batch tracking, not unit-level traceability.
- Is traceability visible during NPI transitions? Ask whether NPI units are tagged and tracked separately from steady-state production.
- Can Operations see the escalation logic, not just QA? Shared visibility prevents containment from being silently downgraded.
- Can QA verify the protocol is enforced, not merely documented? Ask for evidence of a real contained failure — not a theoretical capability.
Traceability protocols don’t have to be a source of friction. When both teams approve the same minimum standard — unit identity, gate enforcement, bound test data, exception handling, NPI visibility, and escalation rules — traceability stops being paperwork and starts being shared operating infrastructure.
Fewer broad stoppages. Faster containment. Launches that hold together under real production pressure. Not a QA win or an Operations win. A program win.
Subscribe to the China Future Sound newsletter for more frameworks on aligning manufacturing quality with operational efficiency.
Our Editorial Process:
Our expert team uses AI tools to help organize and structure our initial drafts. Every piece is then extensively rewritten, fact-checked, and enriched with first-hand insights and experiences by expert humans on our Insights Team to ensure accuracy and clarity.
By: About the China Future Sound Insights Team
The China Future Sound Insights Team is our dedicated engine for synthesizing complex topics into clear, helpful guides. While our content is thoroughly reviewed for clarity and accuracy, it is for informational purposes and should not replace professional advice.